AI Reading Notes: Deep Learning and Large Language Model Basics
GPT High level understandings
- Computational Irreducibility: Some computation can’t be reduced to something quite immediate.
- Tension between Learnability and computational irreducibility. Learning is to compress data by leveraging regularities inside the data. But computational irreducibility implies there is a limit to regularities where the data can’t be compressed too much.
- Tradeoff between capability and trainability: the more you want a system to make “true use” of its computational capabilities, the more it’s going to show computational irreducibility, and the less it’s going to be trainable. And the more it’s fundamentally trainable, the less it’s going to be able to do sophisticated computation.
- ChatGPT is successfully able to “capture the essence” of human language and the thinking behind it and has the potential to be the “world model”
Popular Neural Network
- Convolutional neural network (CNN)
- Instead of a fully connected feed-forward network, only connect a node to a range of nodes in previous layer
- Mostly used in image processing by convoluting a pixel’s nearby pixel values within a rectangle into it
- It could reduce the size of image to be processed
- It could also capture various features contained in the sliding rectangle of different sizes
- Convolutional networks are simply neural networks that use convolution in place of general matrix multiplication in at least one of their layers.
- 3 stages
- Performs several convolutions in parallel to produce a set of linear activations.
- Each linear activation is run through a nonlinear activation function.
- Apply a pooling function to modify the output of the layer further. A pooling function replaces the output of the net at a certain location with a summary statistic of the nearby
- Reduce the dimension of the feature map to reduce the number of parameters to learn and the amount of computation performed in the network.
- Since each position’s value is the statistics around it, the feature map becomes robust to small variation on a particular position
- Recurrent neural network (RNN)
- Suitable for sequential data like time series and text content
- One node has 2 inputs.
- Input from lower layer
- the node’s previous output
- Pros
- can maintain a memory of past inputs, which allows them to capture the temporal dependencies between words
- Cons
- Suffer from the gradient vanishing and explosion problem during back-propagation.
- Vanishing gradient: As the sequence length increases, the gradient magnitude typically is expected to decrease (or grow uncontrollably), slowing the training process.
- RNNs have difficulty processing long sequences due to decaying memory of past inputs over time, and thus hindering the network’s ability to learn long-term dependencies.
- Exploding gradient problem, in which the gradients grow too large and cause the weights to update in an unstable manner.
- Computationally expensive and difficult to parallelize, limiting their scalability to large datasets.
- Suffer from the gradient vanishing and explosion problem during back-propagation.
- Solution: Long Short-Term Memory (LSTM) which uses gates to control whether to pass the 2 types of input’s through https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- However LSTM is too complicated to implement
- GRUs, on the other hand, have a simpler design with fewer parameters than LSTMs, making them faster to train and easy to deploy.
Attention and Transformer
-
Embedding
- A vector of numbers containing a better, lower dimensional encoding of the meaning of the word and its position
- word2vec : a model to generate high quality embedding
-
2 layers of neural networks

- Input is one hot coding of words. It can contain multiple words
- Hidden layer node size is embedding vector dimensions
- Output layer node size is the number of word to predict
- Output layer outputs the probability of a word
- each word’s embedding is the trained input weight of output layer
-
2 prediction tasks
- Continuous Bag-Of-Words (CBOW): given context words, predict one word which is either the next word, or some middle word
- Skipgram: given one word, predict multiple context words
-
Trained with both positive and negative examples
-
-
ResNet: combine one neural network layer’s output directly with the original input
- Overcome deep neural network’s vanishing gradient problem caused by long path of propagation
-
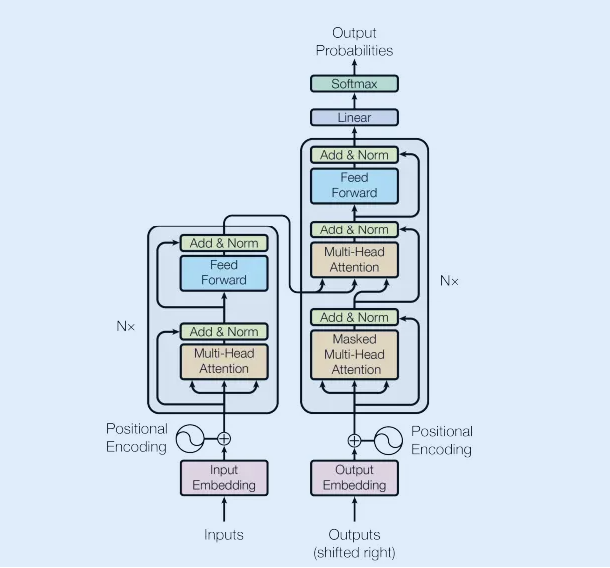
Transformer
-
Attention Layer
- Seq2seq model: an early attention based model for translation

-
Attention is based on RNN
-
It combines all encoder RNN nodes’ output with different weights as an additional input signal to decoder’s attention layer
-
Attention layer can be simplified to multiplication of 3 matrixes: K, Q, V
- In self attention, each embedding are multiplied by 3 weight matrixes to generate K, Q, V
- The 3 weight matrixes are trainable
- The formula is something like softmax(K * Q^T / some value) * V
- The idea is to correlate one word with another and generate output embedding based on correlation result
- The higher several words’ correlation is, the more impact they have in the output embedding
- One attention layer can contain multi heads attentions which means multiple triple of K, Q, V generated from different weight matrixes
- Meaning: understand a sentence from different perspective and join them together finally

- In self attention, each embedding are multiplied by 3 weight matrixes to generate K, Q, V
-
Encoder decoder
- Input embedding is from 2 sources: word embedding and position embedding
- Each model contains multiple encoder and/or decoders
- Each encoder/ decoder contains an attention layer and a feed forward neural network layer
- feed forward neural network layer is where most parameters reside in
- Multi-head attentions generate one embedding for each attention head
- Then these attentions are concatenated and multiplied by a matrix to generate an embedding with same dimension as a single attention’s output
- Then the result is fed into feed forward layer
- There are usually 6 layers of encoders and decoders
- The layers that are closer to the token embeddings represent lower-level token relations, while deeper layers learn to represent higher-level information present in the input sequences.
- Final Linear layer is a fully connected neural network converting output vector to probabilities for each word
- Pros
- Enables parallel processing of the input sequence
- Easy to visualize and understand
- Enables the model to consider the complete input sequence by leveraging
- self-attention
- positional encoding of each word

-
-
Training:
- 2 types of objectives
- Autoregressive (AR) focus on regenerating text sequences
- Autoencoding (AE) aim to reconstruct the original text from corrupted text data
- Steps
- Feed the network with a few hundred billion words of text
- Calculate loss
- Backward propagation with gradient decent
- a couple hundred billion weights to update
- Both input and output words are fed into model during training
- loss: cross-entropy and Kullback–Leibler divergence.
- Cross entropy: error x the probability of error occurance
- KL divergence: difference between 2 distributions
- Fine tuning: update the model on a better, smaller training dataset with more specific purpose
- Reinforcement Learning from Human feedback: Train the model on a dataset which contains human ratings on answers.
- 2 types of objectives
-
Inference:
- Steps:
- Convert word token into 2 embeddings. One for token value. The other for token position.
- Operate the embeddings through many layers of attention and neural network and generate a new embedding
- The attention and neural network corresponds later token with its previous token to understand the context and merge with the GPT’s own compressed knowledge obtained during training
- The final embedding is converted into a list of probabilities for each token to find the output token
- Temperature: how often lower-ranked token output will be used, and for essay generation,
- Steps:
-
Encoder vs Decoder
- Encoder’s self attention is bi-directional. Each token can have attention to any token in the sentence including both previous token and later token
- Decoder’s token can only have attention to previous token
- This is achieved by masking future node’s attention in input layer
- Encoder is good at various predictive modeling tasks such as classification and understanding.
- Decoder is good at text generation task
-
Various models
- BERT: encoder only, trained with Autoencoding (AE) goal
- GPT-1 (2018, 117 million parameters) did not exhibit emergent capabilities and heavily relied on fine-tuning for individual downstream tasks.
- GPT-2 (2019, 1.5 billion parameters) introduced the phenomenon of in-context learning for a few tasks, and improved its tokenizer by using Byte-level Encoding (BLE) on top of the original spacy tokenizer used in GPT-1.
- GPT-3 (2020, 175 billion parameters) has surprisingly demonstrated strong in-context learning capabilities, including zero-shot and few-shot learning abilities
- ChatGPT: GPT-3 + fine-tuned by InstructGPT method
- InstructGPT combines supervised learning of demonstration texts from labelers, then with reinforcement learning of generation text scoring and ranking
- Mistral 7B
- Uses Mixture of expert structure
- Divide each feed forward neural network layer into multiple smaller feed forward neural network with less parameters
- Train each smaller network separate
- During inference, use an arbitrator to select one feed forward network to use
- Better scalability



Fine Tuning
- Fine tune the full model with a smaller but better dataset such as Q & A dataset
- LoRA & QLoRA:
- Transform the Feed Forward Neural Network’s large parameter matrix into multiplication of 2 low rank matrixes with much fewer parameters
- Fine tune the model on the 2 low rank matrixes
- Quantize the matrix weight into less bits
- Instruction Tuning
- The fine tuning dataset is like {human instruction, output}
- Closer to real Q & A task
- Self Play Fine Tuning SPIN
- Iteratively generate new version of model based on synthetic data generated from previous version of data
- Goal is to create a distilled model which can produce data closer to fine tuning instruction dataset
- During training, penalize the result if the loss converges too fast to avoid overfitting
- Reinforcement Learning with Human Feedback RLHF
- Basic idea is to train a model based on human evaluation score in addition to instruction dataset because there might be low quality data in instruction dataset
- steps:
- Fine tune model
- Train a reward model on base model and with human feedback dataset
- Fine tune the base model with reward model’s evaluation
- The loss is (Reward - KL divergence of new model and base mode)
- This is called Proximal Policy Optimization
- This KL term serves two purposes.
- it acts as an entropy bonus, encouraging the policy to explore and deterring it from collapsing to a single mode.
- Second, it ensures the policy doesn’t learn to produce outputs that are too different from those that the reward model has seen during training.
- Do step 2-4 iteratively
- Various ways of human feedback
- compare 2 output
- rank 4 - 9 outputs each time and convert the ranking into comparison of 2 outputs format
- Various reward model
- safetyness
- helpfulness
- Rejection sampling
- Sample multiple response and pick the one with highest reward during training
- DPO Direct Preference Optimization
- Simplify the iterative reward model training and base model fine tuning process into a simple fine tuning process
- by deducting a straight forward loss function based on PPO and reward calculation
- RLAIF: with AI feedback
- Use LLM to provide rating and feedback directly with chain of thoughts prompting and few shot prompting

- Prefix Tuning
- Train the model to append some default prefix tokens to the input prompt.
- The default prefix may not be human understandable. It is just something for LLM
Computation Optimization
- Flash Attention
- Change the order of attention’s matrix multiplication calculation
- More computation but less memory used
- Reduce GPU memory IO and the overall performance is greatly improved
- Linear Attention:
- Convert attention’s softmax function to a linear function
- Lightning Attention:
- Divide attention’s matrix into smaller block of matrixes and run calculation per block
- Utilize GPU’s architecture to run multiple blocks’ calculation in parallel on multiple GPUs and shared memory more efficiently
- Quantization
- Quantize weights from Float type to integer with less bits
- Post-Training Quantization (PTQ): converting the weights of an already trained model to a lower precision without any retraining.
- might degrade the model's performance slightly due to the loss of precision in the value of the weights.
- Quantization-Aware Training (QAT): integrates the weight conversion process during the training stage.
- superior model performance, but it's more computationally demanding. A highly used QAT technique is the QLoRA.
- Speculative decoding
- Approximate a large model with a small model whose parameters are 2 order less during inference time
- Steps
- Sample n token from small model for inference
- validate n token in large model in parallel by running feeding large model with n prefixes and check if it outputs expected next token
- If large model’s output probability is smaller than small model on same output token, then reject the result and re-sample the small model starting from this token with a probability
Reference
- What Is ChatGPT Doing … and Why Does It Work?
- Deep learning text book
- What are embeddings
- Understanding LSTM Networks
- Evolution of Neural Networks to Large Language Models in Detail
- The Illustrated Word2vec
- A Dummy’s Guide to Word2Vec
- Neural Machine Translation (seq2seq) Tutorial
- Attention? Attention!
- The Illustrated Transformer
- Residual Connection
- What is purpose of stacking N=6 blocks of encoder and decoder in transformer?
- Transformer’s Encoder-Decoder
- An In-Depth Look at the Transformer Based Models
- LoRA: Low-Rank Adaptation of Large Language Models
- QLoRA: Efficient Finetuning of Quantized LLMs
- Mistral 7B
- Scaling Instruction-Finetuned Language Models
- Instruction Tuning for Large Language Models: A Survey
- Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
- Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
- Fast Inference from Transformers via Speculative Decoding
- Prefix-Tuning: Optimizing Continuous Prompts for Generation
- An Introduction to Training LLMs Using Reinforcement Learning From Human Feedback (RLHF)
- Illustrating Reinforcement Learning from Human Feedback (RLHF)
- LLM Training: RLHF and Its Alternatives
- Learning to summarize from human feedback
- Proximal Policy Optimization Algorithms
- RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Comments
Post a Comment